[FRONT]
- [FRONT] 프론트엔드 쿠키 이슈 해결하기
- [FRONT] Nuxt Proxy 설정과 활용
- [FRONT] 웹 캐시 전략과 구현
- [FRONT] Next.js와 Nuxt.js 비교 분석
- [FRONT] Monorepo vs Multi-repo vs Monolith 아키텍처
- [FRONT] mitmproxy를 활용한 디버깅
- [FRONT] Storybook 활용 가이드
- [FRONT] Vercel Turbopack 소개
- [FRONT] 캐시와 캐싱 전략
- [FRONT] SWC 컴파일러 이해하기
- [FRONT] 인터섹션 옵저버로 인터섹션 여부 감지하기
- [FRONT] BroadcastChannel 사용해서 같은 도메인 브라우저 간 통신하기
- [FRONT] DOM이벤트 버블링(Bubbling)과 캡처링(Capturing)
- [FRONT] XSS와 CSRF
- [FRONT] 웹 성능 최적화
- [FRONT] 브라우저 렌더링 과정
- [FRONT] 웹 접근성
- [FRONT] URL과 Domain 정확히 이해하자 (url구조)
- [FRONT] HTTP 헤더 이해하기
- [FRONT] 🍪 Cookie 보안의 모든 것: 탈취부터 방어까지
- [FRONT] 프론트엔드 기술은 어떻게 발전해왔는가?
- [FRONT] www.google.com 입력하면 일어나는 일 — DNS부터 렌더링까지
알고있으면 너무 좋은 프론트엔드 WEB API 파헤쳐보자
들어가며
프론트엔드 기술은 어떻게 발전해왔을까? 웹은 단순 문서 공유에서 시작해 HTML, CSS, JavaScript를 거쳐 SPA와 SSR까지 발전하며 사용자 경험과 검색 엔진 최적화 사이의 균형을 찾아왔다. 이 글에서는 웹의 탄생부터 현재의 프론트엔드 생태계까지, 그 발전 과정을 따라가본다.
1. 웹의 탄생과 진화: 단순 문서 공유에서 복잡한 프론트엔드 생태계까지
웹은 단순 문서 공유 시스템에서 시작하여 현재의 복잡한 프론트엔드 생태계로 발전해왔다.
1.1. 웹의 시작: 인터넷과 웹의 구분, 그리고 문서 공유 시스템
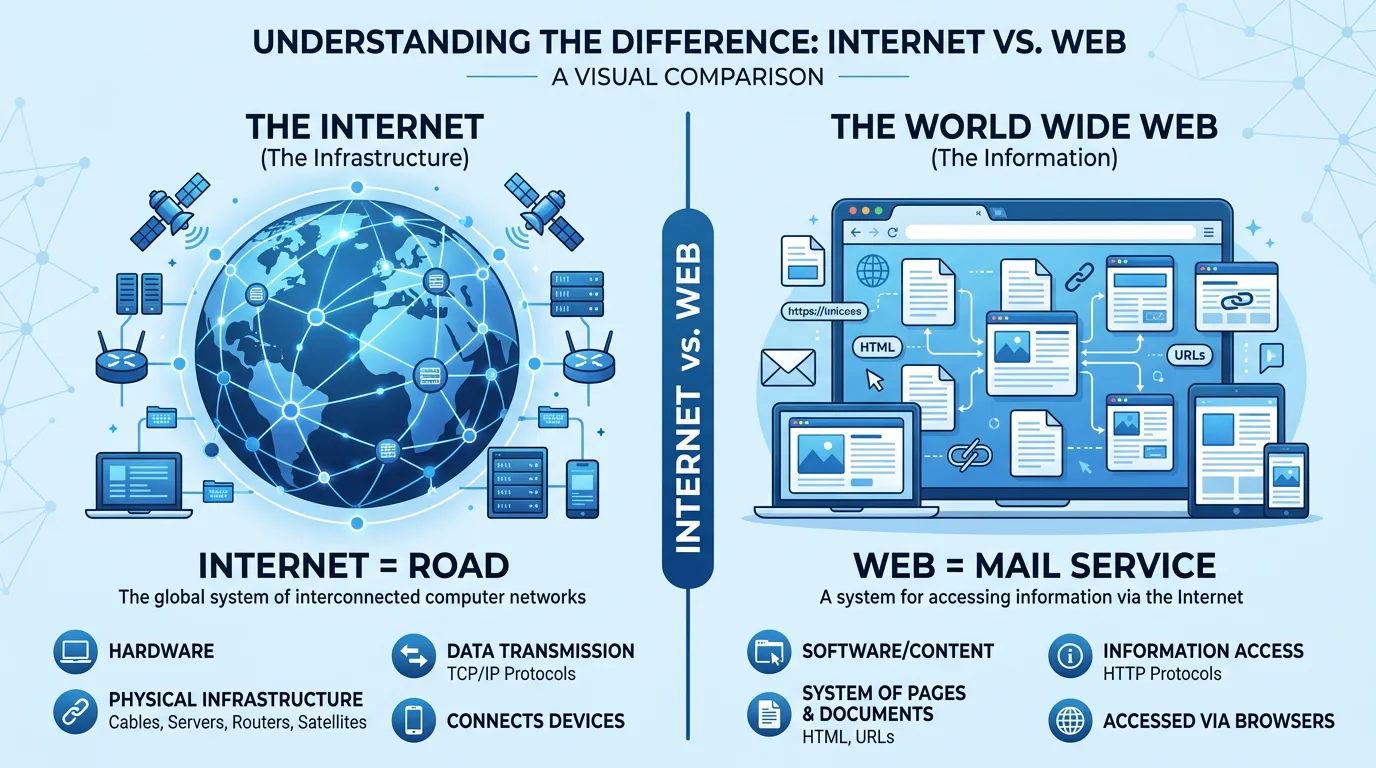
인터넷과 웹은 다른 개념이다.
- 인터넷은 전 세계 컴퓨터를 연결하는 네트워크 인프라, 즉 도로망이다.
- 웹은 이 도로망을 이용하는 우편 시스템으로, 인터넷을 기반으로 문서라는 소포를 URL 주소에 따라 배달한다.
웹은 1989년 팀 버너스리(Tim Berners-Lee)가 제안한 하이퍼텍스트 개념에서 시작되었다. 당시 연구 자료 공유의 어려움을 해결하기 위해, 문서 안에서 다른 문서로 이동하는 링크를 통해 정보를 쉽게 넘나들 수 있게 하는 것을 목표로 했다. 이것이 오늘날 우리가 사용하는 하이퍼링크의 시작이며, HTML의 ‘H(Hypertext)’에 해당한다.
웹의 출발점은 단순한 문서 공유 시스템이었다. 앱이나 쇼핑몰, 유튜브와 같은 복잡한 서비스가 아닌, 연구 문서를 서로 연결하여 공유하는 것이 웹의 근본적인 목적이었다.
1.2. 웹의 3대 기술과 초기 웹 페이지의 모습
1991년, 웹을 만들기 위한 세 가지 핵심 기술이 등장했다.
| 기술 | 역할 |
|---|---|
| HTML (Hypertext Markup Language) | 문서의 구조를 정의하는 언어. 제목(H1), 문단(P), 링크(A) 등의 태그를 사용한다. |
| URL (Uniform Resource Locator) | 문서의 고유한 주소. 어디서든 접근할 수 있게 한다. |
| HTTP (Hypertext Transfer Protocol) | 문서를 요청하고 받는 통신 규칙. 브라우저와 서버 간의 대화 형식을 정한다. |
초기 웹 페이지는 링크가 달린 단순한 텍스트 형태였다. 스타일이나 사진이 거의 없고, 버튼 반응과 같은 인터랙션도 없었다. 이를 정적인 페이지라고 하며, 서버에 저장된 HTML 파일을 그대로 보여주는 방식이었다.
당시 웹은 디자인과 인터랙션이 없는 순수한 문서 형태였다.
1.3. 웹의 시각적 진화: CSS의 등장과 디자인의 시작
웹 페이지를 더 예쁘게 만들고 싶다는 요구가 생겼다. 초기에는 HTML 태그 안에 직접 스타일을 적용했지만, 페이지가 많아질수록 유지보수가 매우 어려워지는 문제를 야기했다. 문서 구조를 정의하는 HTML에 디자인까지 섞여 코드가 복잡해지는 근본적인 문제도 있었다.
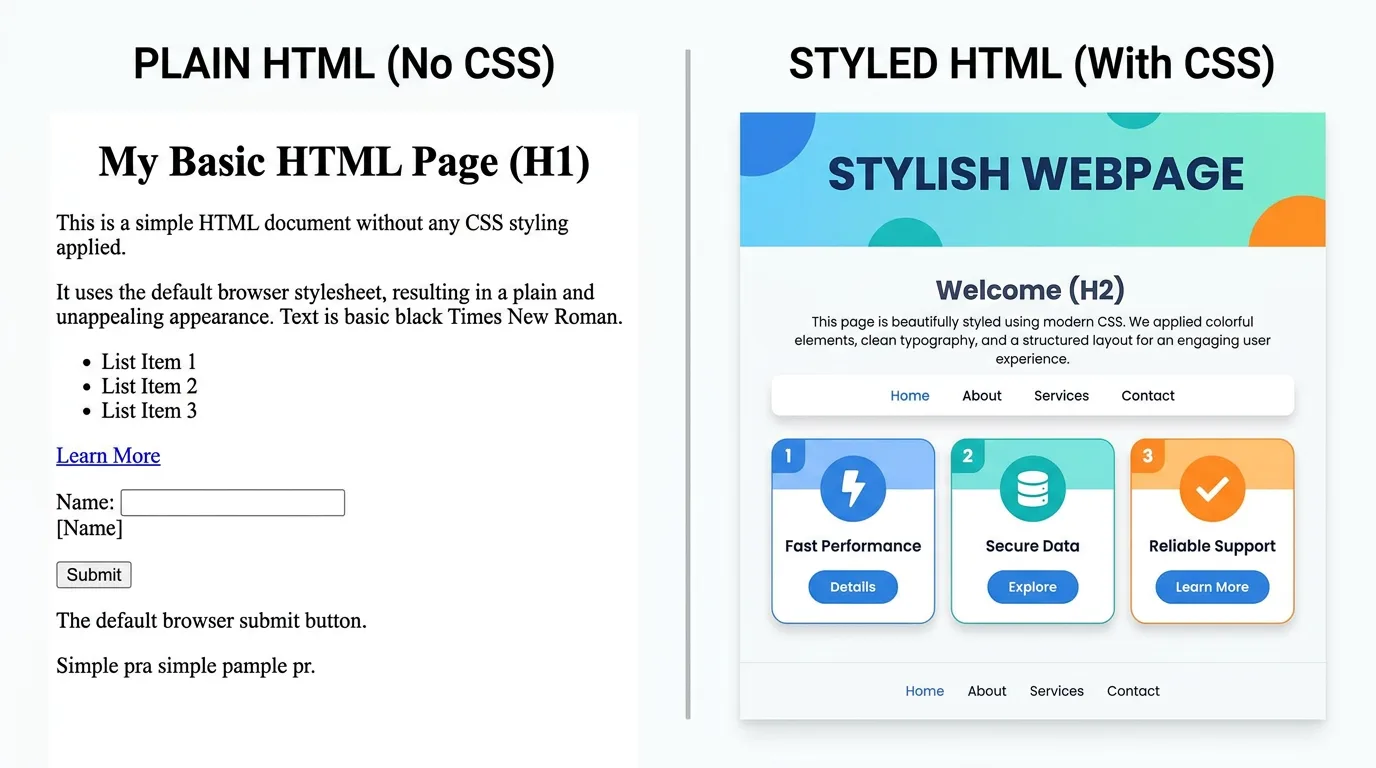
1996년, CSS(Cascading Style Sheets) 등장
- HTML은 내용의 의미만 담고, CSS는 별도 파일에서 디자인(색상, 폰트 크기 등)을 담당하게 되었다.
- CSS 파일 하나만 수정해도 연결된 모든 페이지의 디자인이 한 번에 변경되어 유지보수가 용이해졌다.
Cascade란? 스타일이 위에서 아래로 흘러 적용되는 방식으로, 부모 요소의 스타일이 자식에게 상속되거나 더 구체적인 규칙이 우선 적용되는 CSS의 핵심 작동 원리이다.
1
2
3
4
5
<!-- 나쁜 예: HTML에 직접 스타일 적용 -->
<p style="color: red; font-size: 16px;">안녕하세요</p>
<!-- 좋은 예: CSS 분리 -->
<p class="greeting">안녕하세요</p>
1
2
3
4
5
/* styles.css */
.greeting {
color: red;
font-size: 16px;
}
웹은 읽는 것에서 보는 것으로 진화하기 시작했다. 레이아웃을 잡고 색상을 입히며 폰트를 변경하는 것이 가능해졌다.
1.4. 웹의 동적 변화: JavaScript와 인터랙션의 시작
웹 페이지가 아무것도 반응하지 않는다는 한계가 있었다. 클릭해도 아무런 일이 일어나지 않는 정적인 상태였다.
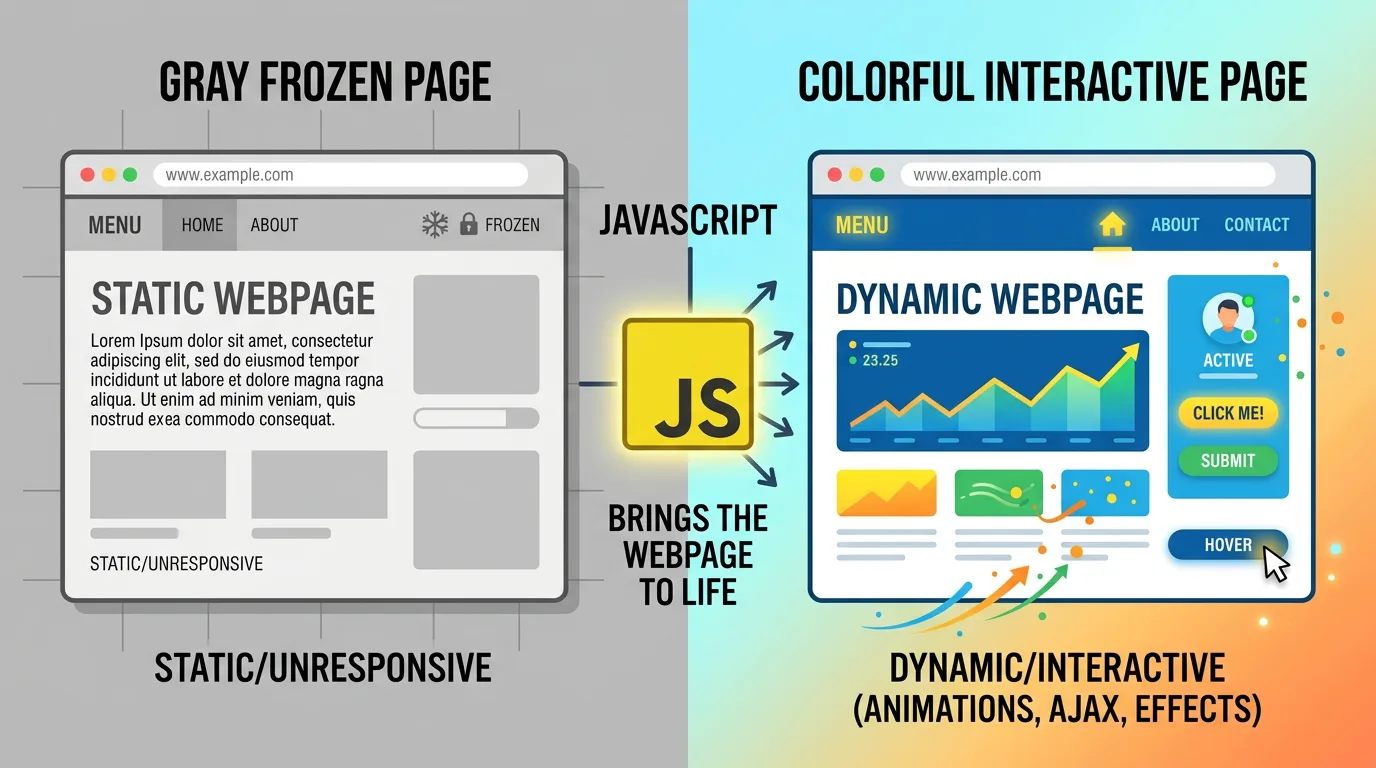
1995년, 단 10일 만에 JavaScript가 개발되었다
Java와 JavaScript는 완전히 다른 언어이며, 이름이 비슷한 것은 당시 Java의 인기에 편승하기 위한 마케팅 때문이었다.
JavaScript는 브라우저 안에서 실행되는 유일한 언어로, HTML과 CSS가 화면을 그리는 역할을 하는 것과 달리 실제 동작을 수행한다.
JavaScript 덕분에 브라우저에서 다양한 동적 기능을 구현할 수 있게 되었다.
- 이벤트(Event): 사용자의 클릭, 키 입력 등 행동에 대한 신호를 감지
- DOM 조작(DOM Manipulation): 브라우저가 HTML을 읽어 생성한 내부 지도(DOM)를 통해 원하는 요소를 찾고, 글자나 색상을 바꾸거나 새로운 요소를 추가하는 등 화면을 실시간으로 변경
1
2
3
4
5
// 이벤트 감지 + DOM 조작 예시
document.getElementById("myButton").addEventListener("click", function () {
document.getElementById("message").textContent = "버튼이 클릭되었습니다!";
document.getElementById("message").style.color = "blue";
});
HTML이 무대 세팅이라면, DOM 조작은 공연 중 소품을 바꾸는 것에 비유할 수 있다. 페이지 새로고침 없이도 관객이 보는 화면을 실시간으로 바꾸는 연출이 가능해진다.
웹은 드디어 사용자의 행동에 반응하기 시작했다.
1.5. 브라우저 전쟁과 렌더링 과정: 표준화의 필요성
1990년대 후반부터 넷스케이프와 인터넷 익스플로러 간의 브라우저 전쟁이 벌어지면서, 각 브라우저가 자체적인 방식으로 기능을 추가하고 표준 없이 작동했다. 이로 인해 같은 HTML 코드를 사용해도 브라우저마다 다르게 보이는 크로스 브라우저 이슈가 발생하여 개발자들이 어려움을 겪었다.
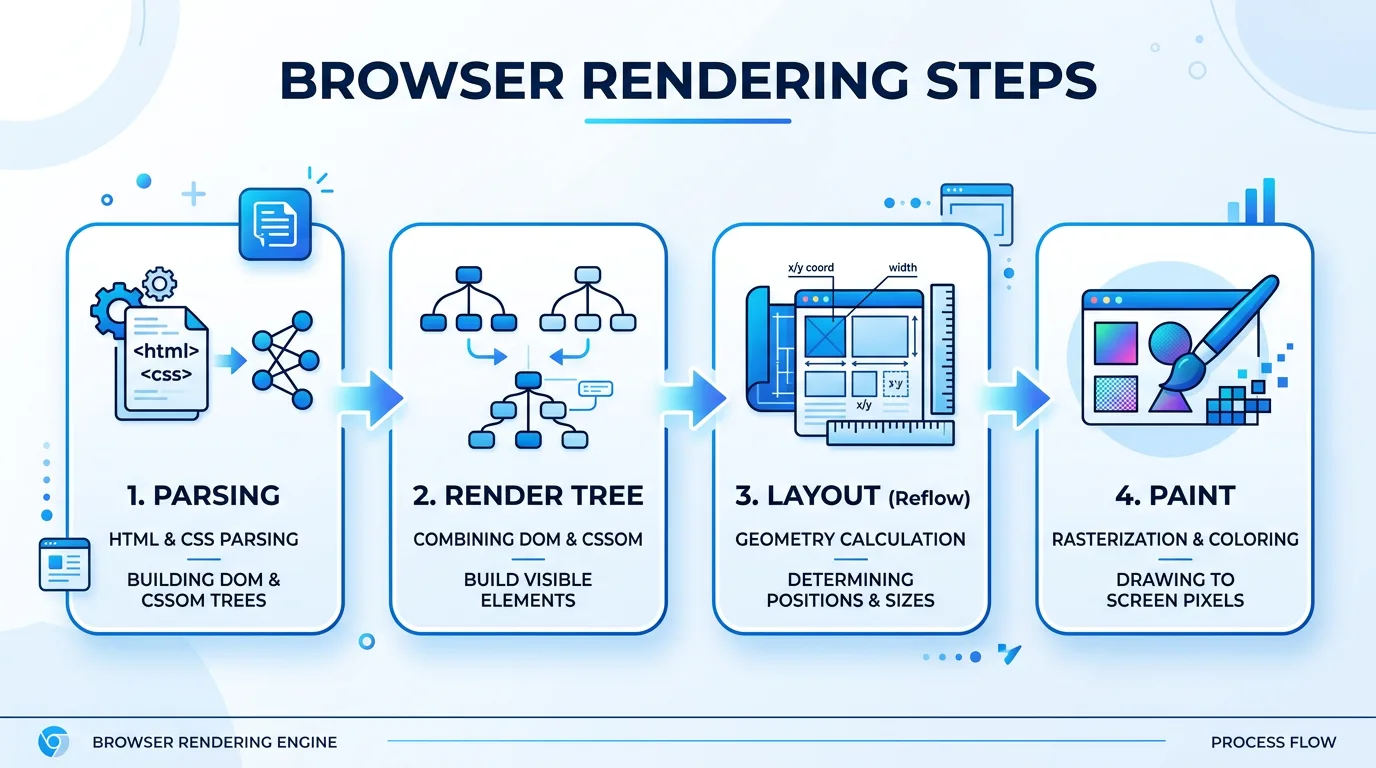
브라우저의 렌더링 과정
| 단계 | 이름 | 설명 |
|---|---|---|
| 1 | 읽기 (Parsing) | 브라우저가 HTML과 CSS 파일을 읽어 페이지 요소와 스타일 정보를 파악 |
| 2 | 그릴 목록 추리기 (Render Tree) | 읽은 내용 중 실제로 화면에 보여줄 요소만 골라냄 (숨김 처리된 요소 제외) |
| 3 | 자리 잡기 (Layout) | 각 요소가 화면 어디에 얼마나 크게 놓일지 좌표와 크기를 계산 |
| 4 | 색칠하기 (Paint) | 자리 잡힌 요소들에 색상, 이미지, 테두리 등을 입혀 화면을 완성 |
리플로우(Reflow)
JavaScript로 DOM을 수정하면 레이아웃 계산을 다시 해야 하는데, 이를 리플로우라고 한다. 리플로우가 많이 발생하면 성능이 저하되어 버벅거림이 발생한다.
프론트엔드 최적화의 핵심 중 하나는 리플로우를 최소화하는 것이다.
1.6. 코드의 복잡성 증가와 라이브러리의 등장: jQuery와 React
웹이 쇼핑몰, 소셜네트워크 등으로 확장되면서 JavaScript 코드가 폭발적으로 늘어났다. 10일 만에 만들어진 JavaScript는 대규모 애플리케이션을 만들기에 적합하지 않아 코드가 복잡해지고 관리가 어려워졌다.
2006년 — jQuery의 등장
jQuery는 DOM 조작 방법을 통일하고 크로스 브라우저 문제를 해결하여 개발 편의성을 크게 높였다.
1
2
3
4
5
// Vanilla JS
document.getElementById("myElement").style.display = "none";
// jQuery — 훨씬 간결
$("#myElement").hide();
2013년 — React의 등장
웹이 더 복잡해지면서 jQuery만으로는 부족해졌고, React가 등장했다. React는 “데이터가 바뀌면 화면은 알아서 바뀐다”는 철학을 바탕으로, 개발자는 데이터 관리에 집중하고 화면 업데이트는 React가 담당하는 구조를 제시했다.
React의 핵심 개념 세 가지
| 개념 | 비유 | 설명 |
|---|---|---|
| 추상화 | 커피 머신 | 복잡한 내부 동작은 숨기고 간단한 명령만으로 사용 |
| 재사용성 | 쇼핑몰 상품 카드 | 한 번 만든 컴포넌트를 내용만 바꿔 어디서든 재사용 |
| 상태 관리 | 장바구니 | 앱이 기억해야 하는 정보를 체계적으로 관리하여 버그 방지 |
이 시기부터 프론트엔드는 단순 디자인 구현이 아닌, UI 아키텍처 설계, 상태 관리, 성능 최적화 등을 담당하는 엔지니어링 영역으로 변화했다. “웹 퍼블리셔”라는 직군이 “프론트엔드 개발자”라는 용어로 대체되기 시작했다.
1.7. JavaScript 생태계 확장: Node.js와 NPM
라이브러리가 많아지면서 코드 공유 및 관리의 새로운 문제가 발생했다. 이전에는 라이브러리를 공식 사이트에서 직접 다운로드하여 프로젝트에 넣어야 했고, 버전 관리 및 충돌 해결도 직접 해야 하는 번거로움이 있었다.
2009년 — Node.js의 등장
Node.js는 JavaScript를 브라우저 밖에서도 실행할 수 있게 만들었다. JavaScript 코드가 실제로 돌아가는 환경인 런타임 역할을 하며, 개인 컴퓨터나 서버에서도 JavaScript를 실행할 수 있게 되었다.
NPM(Node Package Manager)의 등장
NPM은 프로그래밍 세계의 앱 스토어처럼, 전 세계 개발자들이 만든 라이브러리 패키지를 명령어 한 줄로 쉽게 다운로드하고 설치할 수 있게 한다.
1
2
3
4
# 명령어 한 줄로 라이브러리 설치
npm install react
# package.json — 프로젝트의 의존성 명세서
- package.json: 프로젝트가 사용하는 라이브러리(의존성)와 버전을 명세하여 어느 컴퓨터에서든 동일한 환경을 재현
- 의존성(Dependency): 라이브러리 간의 복잡한 연쇄 관계를 NPM이 자동으로 관리
프론트엔드는 이제 부품을 조립하듯 코드를 가져다 쓰는 조립식 산업이 되었다.
1.8. 코드 최적화와 배포: 빌드 과정의 등장
라이브러리와 코드량이 많아지면서, 개발자가 작성한 코드와 실제 서비스에 올라가는 코드 간의 차이 문제가 발생했다.
- 최신 JavaScript 문법을 사용해도 오래된 브라우저에서 이해하지 못하는 문제
- 개발 편의를 위해 나눈 여러 파일이 요청 수를 늘려 느려지게 만드는 문제
- 주석, 긴 변수명, 디버그용 코드 등이 용량 낭비를 초래하는 문제
이러한 문제를 해결하기 위해 빌드(Build)라는 과정이 생겼다.
| 과정 | 설명 | 도구 예시 |
|---|---|---|
| 트랜스파일링 | 최신 JS 문법을 오래된 브라우저도 이해할 수 있는 표준 문법으로 자동 번역 | Babel |
| 번들링 | 수십, 수백 개의 흩어진 파일들을 하나 또는 몇 개로 묶어 파일 요청 수를 줄임 | Webpack, Vite |
| 트리 쉐이킹 | 한 번도 사용되지 않은 코드를 자동으로 제거하여 파일 크기를 줄임 | — |
| 프로덕션 최적화 | 주석, 공백, 긴 변수명 등을 제거하여 파일 크기를 최대한 줄임 | — |
1
2
# 빌드 명령어
npm run build
간단한 목업 수준은 HTML, CSS, JS 파일 3개로 실행될 수 있지만, 웹 애플리케이션은
package.json파일이 있는 상태에서 빌드 과정을 거쳐 배포된다.
1.9. 사용자 경험 향상: MPA에서 SPA로
기존 웹은 페이지 이동 시 전체를 새로 불러오는 MPA(Multi Page Application) 방식이었다. 페이지마다 별도의 HTML 파일이 있고, 이동할 때마다 서버에서 새 파일을 받아와 화면이 잠깐 깜빡이는 현상이 발생했다.
스마트폰 앱처럼 부드러운 화면 전환 경험에 대한 요구가 생기면서 SPA(Single Page Application)가 등장했다.
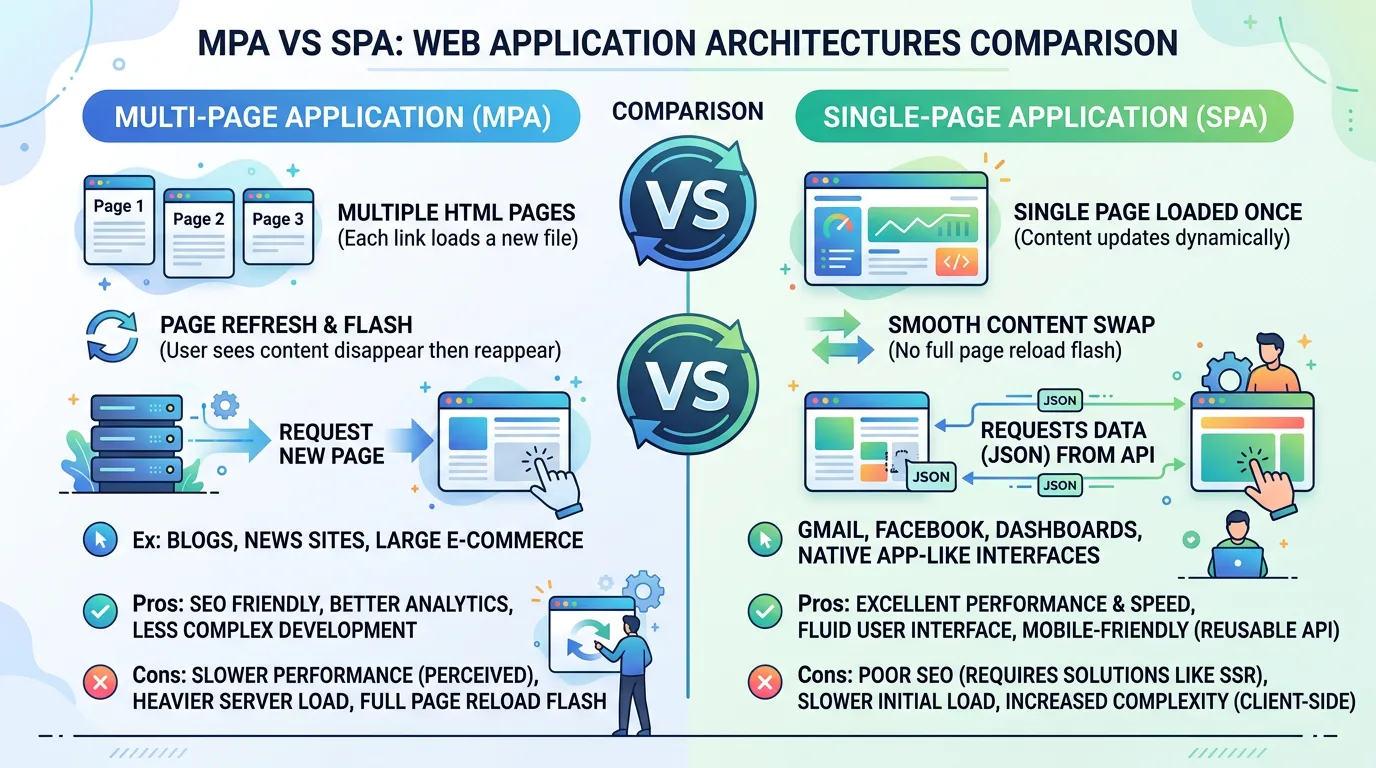
MPA vs SPA
| MPA | SPA | |
|---|---|---|
| HTML 파일 | 페이지마다 별도 | 하나 |
| 페이지 전환 | 서버에서 새 HTML 로드 (깜빡임) | JavaScript가 화면만 교체 (부드러움) |
| 라우팅 | 서버 사이드 | 클라이언트 사이드 |
| UX | 전통적 | 앱에 가까운 경험 |
클라이언트 사이드 라우팅: URL은 바뀌는 것처럼 보이지만 실제로는 페이지 이동 없이 JavaScript가 화면만 교체하는 방식이다.
SPA의 장점은 빠른 전환, 상태 유지, 모바일에 최적화된 UX이다. 웹이 앱처럼 행동하기 시작하면서 프론트엔드 개발은 완전히 다른 차원으로 발전했다.
1.10. 프론트엔드 역할의 확장과 API의 중요성
SPA의 등장으로 프론트엔드 개발이 복잡해지면서 역할이 분리되었다.
과거: HTML, CSS로 디자인을 구현하는 웹 퍼블리셔가 백엔드 개발자에게 화면을 넘겨주는 방식
현재: 프론트엔드 개발자가 React 같은 프레임워크로 복잡한 UI 로직을 짜고, 백엔드의 API를 호출하여 데이터를 받아와 화면을 그리는 모든 과정을 담당
API(Application Programming Interface)
API는 백엔드가 제공하는 데이터 창구 역할을 한다. 프론트엔드와 백엔드 간의 데이터 교환 규칙을 정해놓은 것으로, 프론트엔드는 필요할 때마다 API를 통해 백엔드로부터 데이터를 받아와 화면을 구성한다.
1
2
3
4
5
6
┌──────────────┐ API 요청 ┌──────────────┐
│ │ ──────────────→ │ │
│ 프론트엔드 │ │ 백엔드 │
│ (화면 담당) │ ←────────────── │ (데이터 담당) │
│ │ JSON 응답 │ │
└──────────────┘ └──────────────┘
이 구조를 프론트엔드와 백엔드의 분리라고 하며, 서버는 데이터를 주는 역할만 하고 화면 구현은 프론트엔드가 책임지게 되었다.
1.11. SPA의 단점과 SSR의 재등장: SEO와 로딩 속도 문제
SPA는 강력한 UX를 제공하지만 두 가지 치명적인 단점이 있다.
- 초기 로딩 느림: 모든 화면을 위한 번들 크기가 커져 사용자는 하얀 화면만 보는 시간이 길어진다.
- SEO 약화: 검색 엔진 크롤러가 JavaScript 실행 전의 빈 HTML만 인식하여 페이지 내용을 제대로 파악하지 못한다.
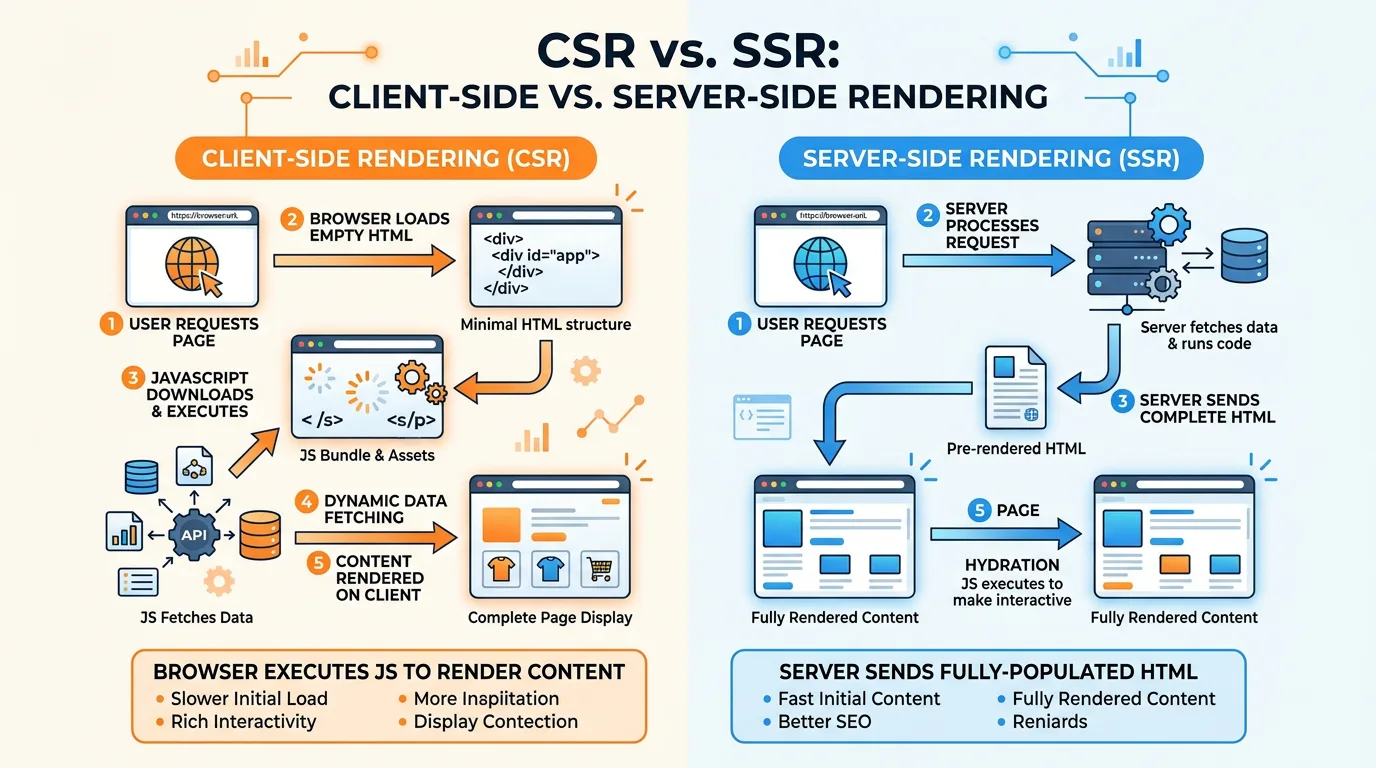
CSR vs SSR
| CSR (Client-Side Rendering) | SSR (Server-Side Rendering) | |
|---|---|---|
| 렌더링 위치 | 브라우저 | 서버 |
| 초기 로딩 | 느림 (빈 HTML → JS 실행) | 빠름 (완성된 HTML 바로 표시) |
| SEO | 약함 | 강함 (크롤러가 내용을 바로 읽음) |
| 서버 부하 | 낮음 | 높음 |
하이드레이션(Hydration)
SSR로 받은 정적인 HTML에 JavaScript를 주입하여 인터랙티브하게 만드는 과정이다. 마른 식물에 물을 주면 살아나는 것에 비유할 수 있다.
최근에는 SSR과 CSR을 상황에 따라 섞어 쓰는 하이브리드 방식(예: Next.js)이 대세이다.
OG 태그: URL 공유 시 미리 보기 이미지, 제목, 설명을 보여주는 오픈 그래프 태그는 SSR 환경에서 더 잘 동작한다.
기술은 항상 트레이드 오프(Trade-off)를 가진다. SPA는 UX를 얻고 SEO를 잃었으며, SSR은 SEO를 얻고 서버 부하를 고려해야 한다.
2. 프론트엔드 개발의 역사적 흐름 요약
웹의 역사는 문제를 해결하면 새로운 문제가 발생하는 식으로 끊임없이 진화해왔으며, 이 과정에서 프론트엔드 개발자라는 직군이 탄생하고 독립적인 기술 영역으로 자리 잡았다.
타임라인으로 보는 프론트엔드 역사
| 연도 | 사건 | 의미 |
|---|---|---|
| 1989 | 팀 버너스리, 하이퍼텍스트 제안 | 웹의 탄생 — 링크로 연결된 문서 공유 시스템 |
| 1991 | HTML, URL, HTTP 등장 | 웹의 3대 기술 확립 |
| 1995 | JavaScript 개발 (10일) | 웹에 동적 인터랙션 부여 |
| 1996 | CSS 등장 | 구조와 디자인의 분리 |
| 1990s 후반 | 브라우저 전쟁 | 표준화의 필요성 대두 |
| 2006 | jQuery 등장 | DOM 조작 통일, 크로스 브라우저 해결 |
| 2009 | Node.js & NPM 등장 | JS의 서버 진출, 패키지 생태계 형성 |
| 2013 | React 등장 | 컴포넌트 기반 UI, 프론트엔드 엔지니어링의 시작 |
| 현재 | Next.js 등 하이브리드 | SSR + CSR의 균형, AI와의 협업 시대 |
핵심 정리
- HTML이 뼈대를 세우고, CSS가 옷을 입히며, JavaScript가 움직이게 만들었다. AI가 만들어주는 모든 웹 화면은 이 세 가지의 조합이다.
- 브라우저마다 다르게 보이는 문제로 표준화가 시작되었고, 코드 복잡성 증가로 React 같은 라이브러리가 등장했다.
- NPM의 등장으로 코드를 부품처럼 가져다 쓸 수 있게 되었다. AI에게
npm install을 요청하는 것은 바로 이 조립 과정이다. - 빌드 과정이 생기면서 작성한 코드와 실제 배포되는 코드가 달라지기 시작했다.
- 페이지 깜빡임 없이 앱처럼 동작하게 하려는 SPA가 나왔고, 검색 문제 발생으로 SSR이 다시 등장했다.
마치며
프론트엔드 개발자는 디자인 구현자가 아닌, 브라우저와 사용자 경험을 설계하는 독립적인 기술 영역의 전문가가 되었다. 그리고 이 영역에 AI가 들어왔다.
프론트엔드가 “어떻게 보여줄까?”에 대한 것이라면, 백엔드는 “어떻게 처리하고 저장할 것인가?”에 대한 것이다. 이 두 가지를 이해하면 기본적인 웹의 작동 방식에 대한 지도가 머릿속에 그려질 것이다.